An AI assistant now writes and ships code under my name. I review some of what it produces. Most of it I do not. The same setup runs on the desk of every engineer I work with: a model in the editor that drafts the next few lines, a local copy of a smaller model for the work I want to keep off third-party services, and a chat window open for the research I no longer do by hand. None of this is exotic. It is, by mid-2026, how most software gets built.
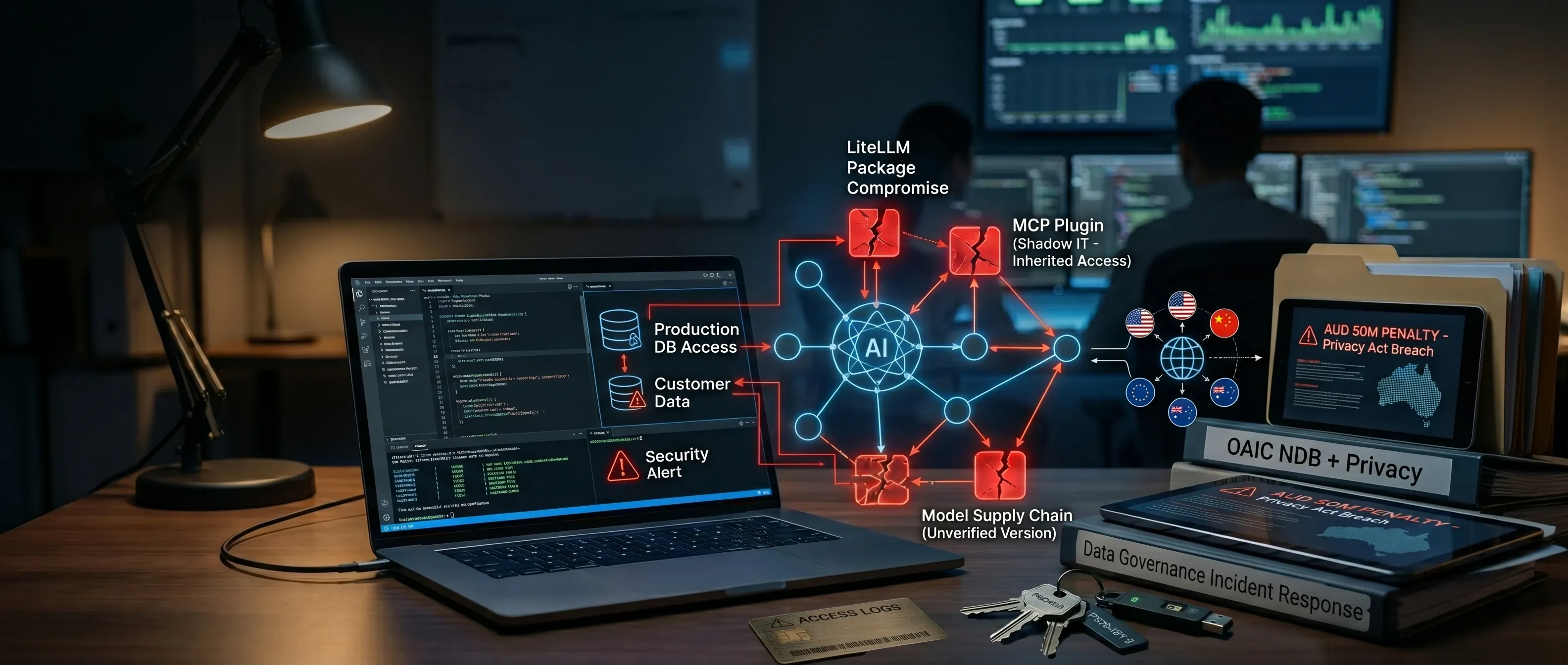
It is also, by an honest accounting, a stack of dependencies I have not audited. The assistant I trust to write code on my behalf runs on top of a tower of other people’s code. So does the local model. So does every plug-in connected to either of them. The trust I extend to the assistant flows to everything underneath it, and almost nobody using these tools has read what sits underneath. The engineers running them daily have not, and the executives funding the spend have not either. That gap is not theoretical. Nearly every layer of this stack has been attacked in the past eighteen months, and when the attack lands it reaches as far as the engineer’s credentials reach, typically into the production cloud, the customer data, and the code that ships to customers tomorrow. This is not just an IT problem. When it goes wrong, the cost comes back as a fine and a breach you have to report, and that falls on the company, not on the engineer who installed the software.
Last month, I wrote about the supply chain at the landscape level: how broad it is, why it goes well past the public code libraries most teams picture when they hear the words. This post is about the part of that landscape I trust the most, and inspect the least: AI tooling.
AI moves too fast for forecasts. What follows is the problem as I see it now, anchored to incidents that have already happened in the open
AI moves too fast for forecasts. What follows is the problem as I see it now, anchored to incidents that have already happened in the open. Every layer I describe has already been attacked at least once. For your business the question is which layer, and you should assume at least one.
I’m writing about supply chain because the compromise lands at install time. The engineer never sees a thing, and the business absorbs the loss before anyone in the room knows it happened. Other AI risks (prompt injection, jailbreaks, what an agent does once you let it act on its own) are real and getting worse, but they at least announce themselves.
If you only have five minutes, skip to the five questions at the end. They are what I would put to your own team this week.
The stack you cannot name
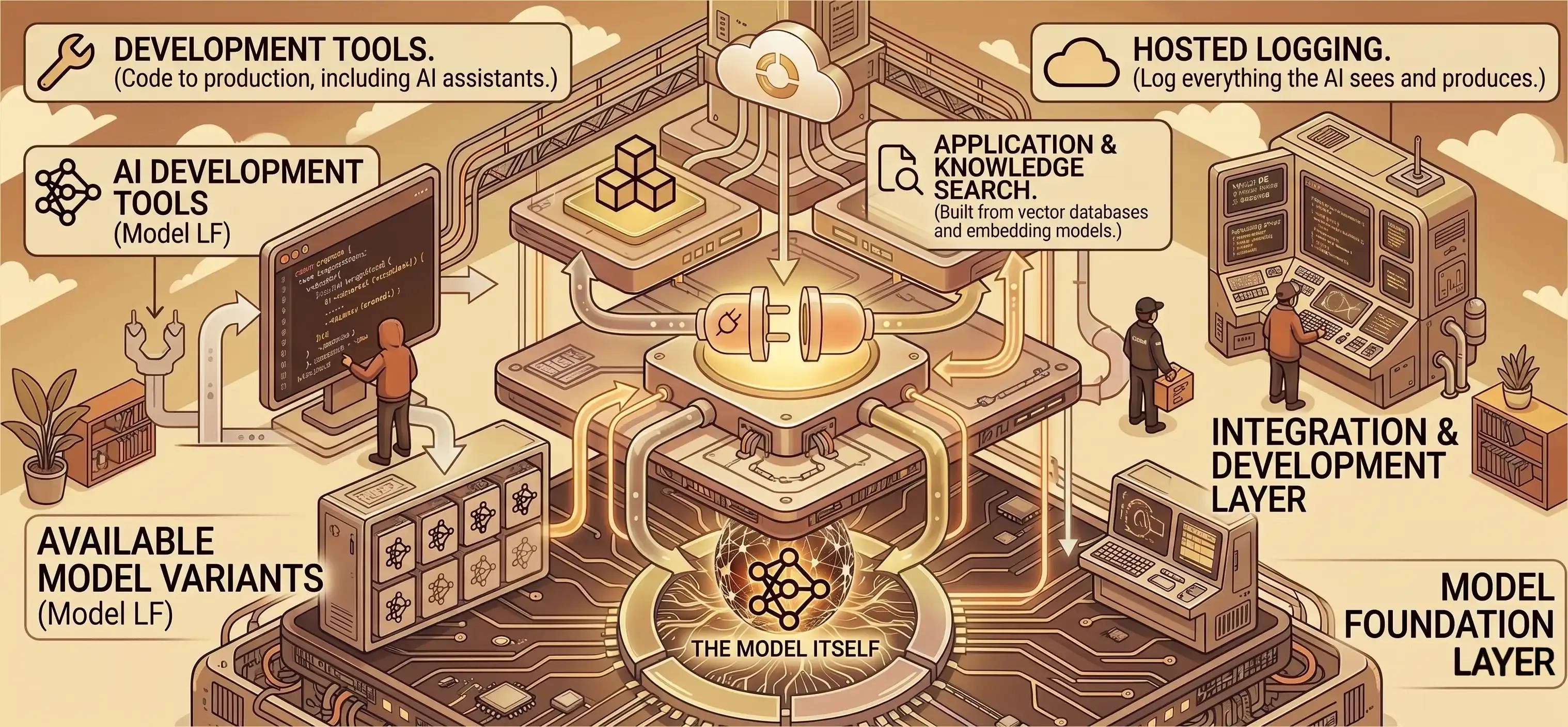
Ask most leaders where their AI supply chain risk lives and the answer is “the model”. It is what regulators write about, what procurement negotiates over, what shows up on the board pack as “the AI we are using”, and the only layer most of them can name.
A production AI system is built from many. Most have already been successfully attacked in the past eighteen months:
| Layer | What it’s built from | What a compromise means |
|---|---|---|
| The model itself | Most public models live on a platform called Hugging Face. | You may not have downloaded what you think you did, because the same platform hosts thousands of community-published variants of popular models under names that look almost identical. |
| The plumbing between the model and your applications | Open-source code libraries pulled from the public catalogue. | A single compromised library sees everything that passes through it, including the prompts carrying your customer data. |
| The systems that let the AI search your internal documents (contracts, customer data, board papers) | Vector databases and embedding models. | A compromise exposes everything in them and can quietly steer the answers the AI gives your staff. |
| The plug-ins that let the AI act on the business’s behalf (sending email, querying customer databases, browsing the web, running commands) | A standard called Model Context Protocol, or MCP, run inside an agent runtime. | A compromise lets an attacker do anything the AI is allowed to do, which means anything the engineer running it can do. |
| The development tools that ship code into production | Used by both engineers and their AI coding assistants. | A compromise ships malicious code into your live systems under a trusted name on the commit, and the change reaches production before the human review catches it. |
| The hosted services that log everything the AI sees and produces | Managed AI platforms and logging services. | A compromise gives an attacker a full record of your prompts, outputs, and customer interactions, and lets them hide their own activity from the team monitoring the system. |
Every layer is trusted on the same act of faith, and an engineer working with AI can add more third-party software in one afternoon than a traditional engineering team would add in a quarter.
This post covers four of the six layers above. Development tools I covered in Part 1; hosted AI like Claude or GPT I cover under sovereignty.
I start with the open-source code, because that is where attacks are hitting hardest right now.
Where the attacks are landing now
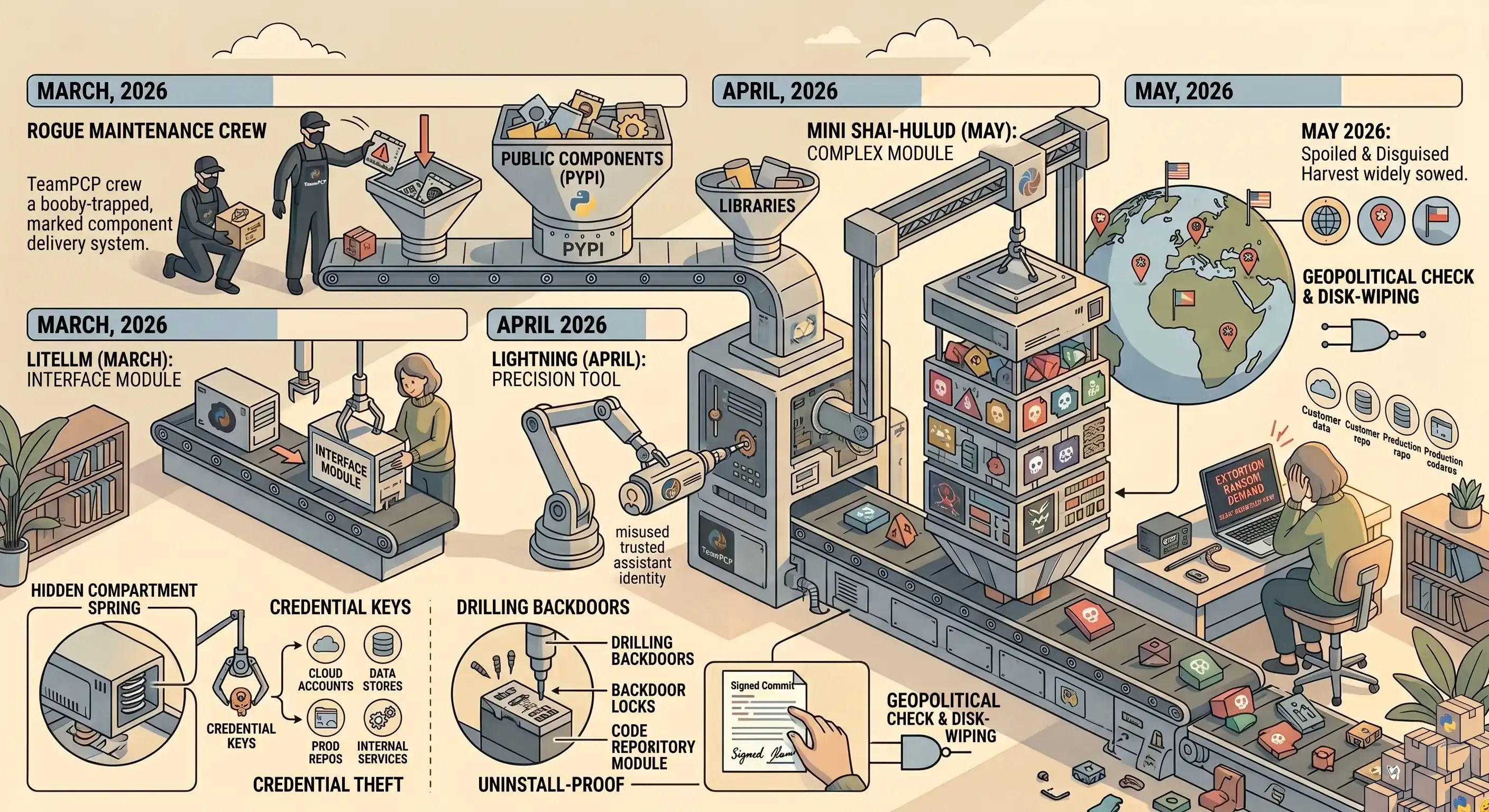
Three Python supply chain attacks in three months, all from the same criminal group, all designed against how engineers using AI actually work: install fast, trust the assistant, skim the changes on screen. Python’s public catalogue (PyPI) is where they landed because the machines its tools reach belong to engineers, who routinely hold credentials to production cloud accounts, customer data stores, and the code repositories that ship to live systems. AI is no longer a specialist’s tool; it sits on every engineer’s laptop now, the SRE’s and the platform engineer’s included, and those are the people holding the widest access of all.
AI is no longer a specialist’s tool; it sits on every engineer’s laptop now, the SRE’s and the platform engineer’s included, and those are the people holding the widest access of all.
LiteLLM, March 2026. LiteLLM is one of the most common ways AI applications reach different model providers through a single interface. In March 2026, two malicious versions sat on the catalogue for about forty minutes before being pulled. Any team running a routine update in that window pulled the malware, which stole every credential on the machine and used them to reach the production cloud accounts and internal services the engineer could access. Investigators linked it to a criminal group called TeamPCP.1
Lightning, April 2026. Five weeks later, the same pattern hit PyTorch Lightning, the training framework AI engineers use to build and fine-tune their own models. Three things make this attack a turning point:
- It slipped past the standard security scan: Most scanning runs at install time; Lightning only activated when the package was actually used.
- Uninstalling did not undo the damage: The stolen credentials had already been used to write trapdoors back into the developer’s own code repositories, so they were now part of the developer’s own work.
- The malicious commits were signed under the AI assistant’s identity: The engineer reviewing them saw an author they already trusted, and skimmed.2
Mini Shai-Hulud, May 2026. A month later, TeamPCP escalated to a wider operation, compromising more than 170 packages across Python and JavaScript, including packages published by Mistral AI. Two details escalate this one further:
- The malware disguised itself as a legitimate Hugging Face library to fool the engineers installing it.
- It carried disk-wiping code that activated only in certain countries, the kind of signature normally seen in state-aligned operations. TeamPCP is not believed to be a state actor. They are a criminal group acting with the capability of one.3
The plug-ins no one is tracking
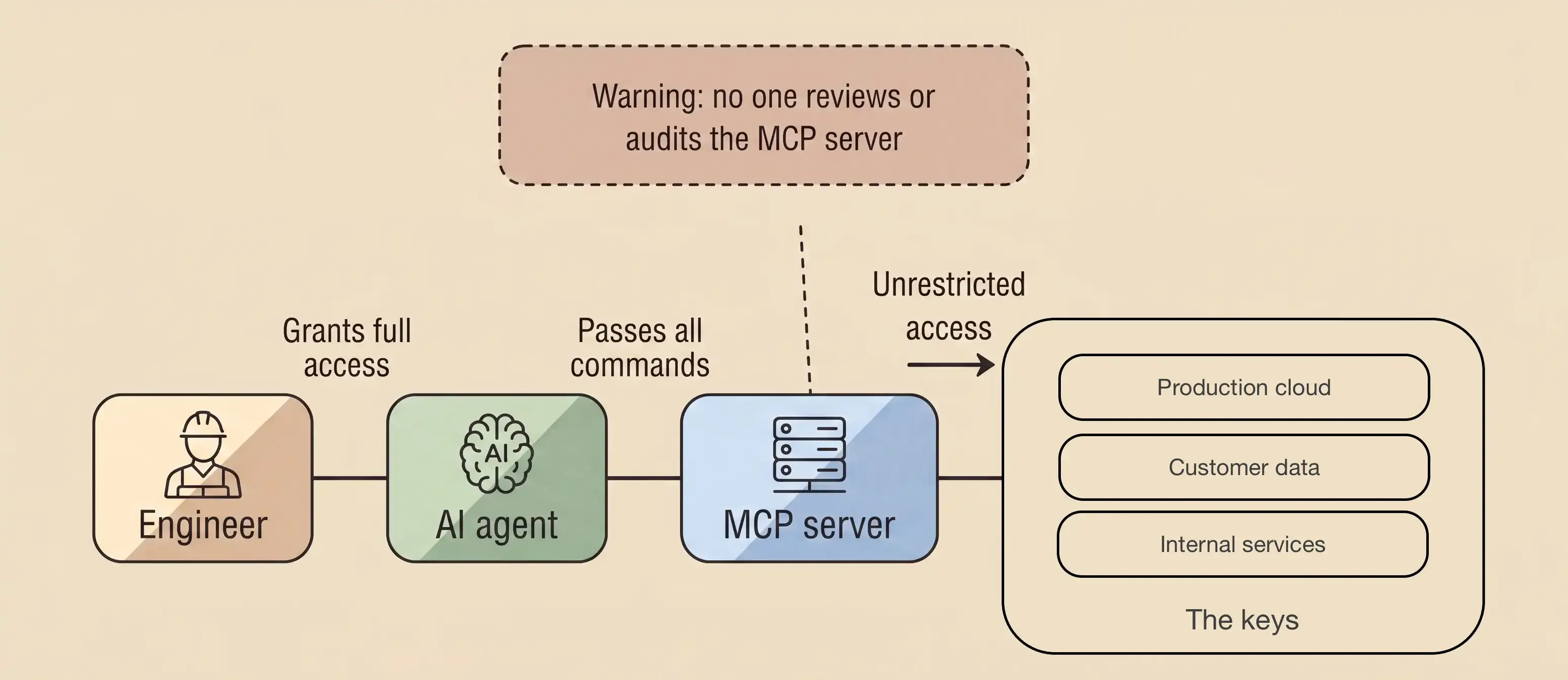
Within the stack you cannot name, MCP is the layer no one can name, and the most dangerous. Model Context Protocol lets an AI agent reach into the rest of the business: read files, query customer databases, send email, run commands. Anthropic published the standard in late 2024. By mid-2025 there were roughly 4,500 public servers and weekly installations had crossed 4.7 million. That was a year ago, and the trajectory has steepened since. Engineers are installing them the way they install any open-source package: from the first search result, on a colleague’s recommendation, without review.
The AI systems your team builds tend to hold some of the widest access of anything you operate: production cloud, customer data, internal services. The engineer working with that AI keeps the keys to all of it on their laptop, and every MCP server they install runs on the same laptop. One compromised server reaches everything the engineer can reach, and the AI acts on that reach at machine speed, under the engineer’s identity. An attacker needs only one weak server out of every one your team has installed, including every piece of code each of those servers depends on.
The attacks have started. The first malicious MCP server hit the public catalogue in September 2025. In April 2026, a single vulnerability in the reference code every other MCP project builds on top of exposed projects with 150 million combined downloads.4 The record is shorter than Python’s because the layer is younger, and it is filling in fast.
I use MCP servers daily. The assistant suggested most of them; a colleague suggested the rest. I have not read the source of any of them, and I could not in any useful timeframe. Neither could your team.
The models you run yourself
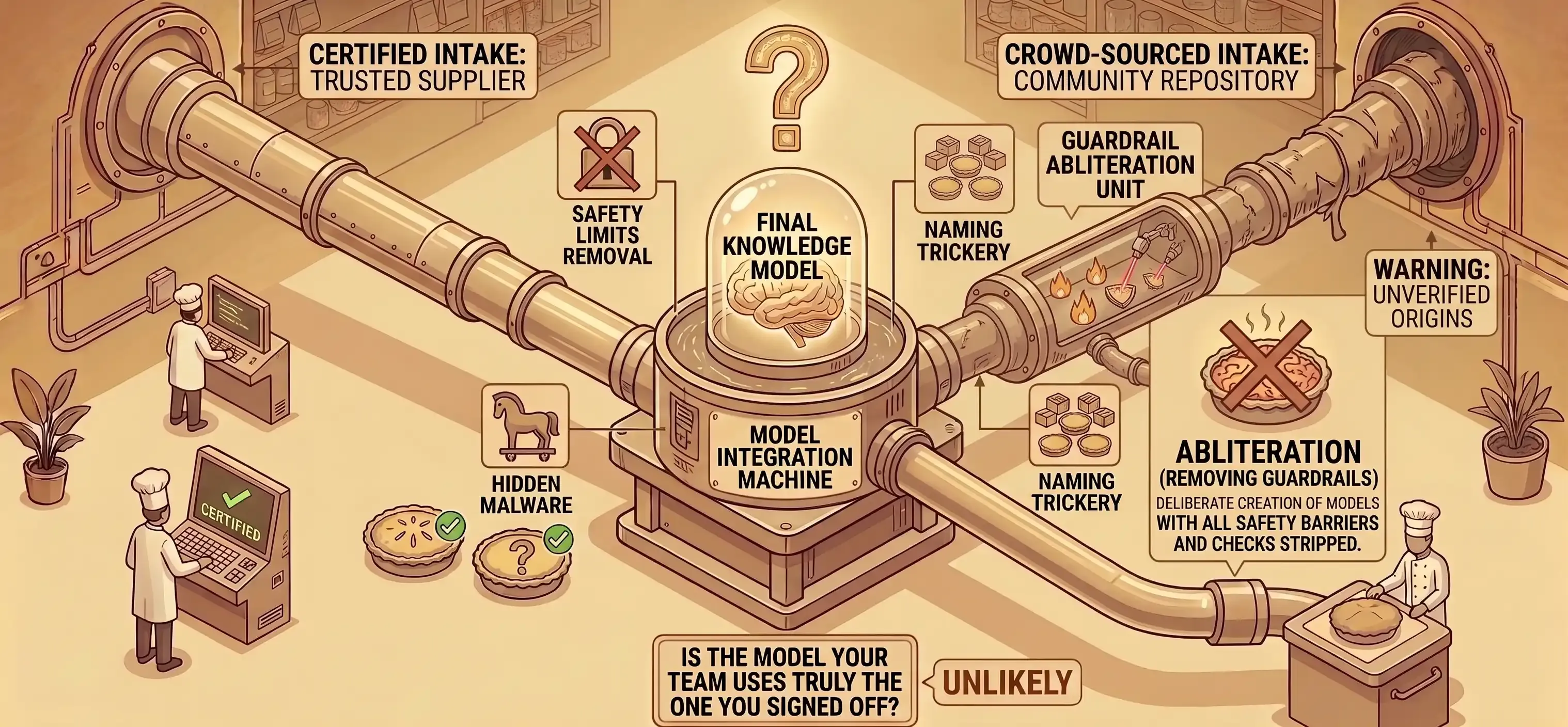
The model supply chain is now a publisher question. What matters is who uploaded the version your engineer downloaded, and what they did to it first.
Most boards do not know which case they are in. The first question is whether your engineers download models and run them on infrastructure your team owns, or whether your AI use is entirely through hosted APIs (Claude, GPT, Gemini, hosted DeepSeek). The first category carries the risks in this section. The second sits one floor up, in the Python libraries that call the model, and is a different question covered under sovereignty below.
The format risk that defined 2024 and 2025 is being closed at the source by major publishers shipping safer formats by default.
What replaced it is harder to defend against. For every popular base model there is a long tail of community-published derivatives on Hugging Face. Gemma 4 is the live example. Google released it on 2 April 2026 with the same internal safety review the proprietary Gemini models go through5. Within weeks the community had published thousands of derivatives next to it, with nothing to mark which is which. google/gemma-4 is from Google. randomguy42/gemma-4-uncensored is from a stranger. Both come up in the same search.
Major publishers run review at scale, so a malicious release from their own accounts is unlikely. The risk is that the version your engineer downloaded did not come from them at all.
Four risks follow.
-
The safety profile of the model can be silently stripped out Abliteration is a 2024 technique that removes the internal weights responsible for refusal. The model still loads, still produces fluent output, still passes most benchmarks. What it cannot do is decline a request, including requests for instructions on building weapons, generating child sexual abuse material, or laundering money. Hugging Face hosted around 600 abliterated models in 2024; over 6,000 by mid-2026.6
-
The version your engineer deploys can behave differently from the version your safety review tested An attacker can hide malicious behaviour inside the model so it only triggers after the engineer prepares it for local use. Your safety review sees the clean version; your team runs the malicious one.7
-
Loading a model can run code on the engineer’s machine This is true for both the old format and the new one, with multiple documented attacks against the platform’s own defences.8 9 10 11 12
-
A compromised publisher account pushes malicious updates under a trusted name Every team that pulls an update gets the malicious version. The pattern mirrors the namespace attacks in the Python layer, without the same scale of attribution yet.
So the question for your team is whether they can prove the model running in production is the one your safety review signed off. For most teams today, the honest answer is no.
The documents you cannot vet
Retrieval-augmented generation gives an AI the ability to read your internal documents and use what it finds to answer questions. The supply chain risk is that every document your AI is allowed to read is now part of it. If an attacker can plant text in any document the AI sees (a support ticket, a contract revision, a scraped web page, an email a customer sent you), they can plant instructions in that text. The AI reads the document, follows the instructions, and acts. Every document your AI is allowed to read is now part of your supply chain.
Every document your AI is allowed to read is now part of your supply chain.
In June 2025, a researcher at Aim Labs sent a single email to a target’s Outlook inbox. The user did nothing. Microsoft 365 Copilot retrieved that email on a later unrelated query, followed the hidden instructions inside it, and sent the most sensitive content from the user’s account to an attacker-controlled server. Microsoft patched the vulnerability and reported no exploitation in the wild. The researchers named the attack EchoLeak; it was the first documented case of an AI assistant being weaponised this way in a production system13. Anyone who can write into the documents your AI reads is now part of your supply chain.
An attacker is not always required. In early 2026, a defect in Microsoft 365 Copilot let it read and summarise emails that customers had explicitly marked confidential, bypassing the data-loss controls that were supposed to keep AI out of those messages. Microsoft confirmed the issue weeks later14. The vendor whose controls decide what your AI can read is upstream of it too.
For Australian organisations, both routes are a notifiable data breach, and neither needs any malicious code: an attacker either breaks into the store holding those documents, or feeds the AI instructions that make it hand the data over.
Sovereignty and state control
Every layer in this post is published by an entity under some government’s authority. The framing so far has been about what attackers do; this last beat is about what your suppliers themselves can be required to do. China requires generative AI services operating in the country to file with the Cyberspace Administration, conform outputs to “core socialist values”, and refuse politically sensitive queries15. The United States restricts the export of advanced AI chips, with the consistent aim of keeping them away from rivals, and has moved towards similar restrictions on model weights16. The European Union’s AI Act is now in force and imposes risk-based obligations on models deployed in the EU. Australian organisations sit inside this lattice without owning any of it.
The supply chain consequence is direct. A model your team runs today may not be the same model six months from now. A US export control might cut you off from updates. A Chinese government direction might quietly change the behaviour of a hosted model you depend on. An open-weight licence might be revoked entirely. Alibaba moved its newest Qwen flagships from open to proprietary in early 2026, after the family had become one of the most-deployed self-hosted model lines globally17. Every prompt sent to a hosted model leaves your jurisdiction along with it, which for Australian organisations is a Privacy Act question long before it is a security question: the supplier you trust answers to a government that can direct it.
the supplier you trust answers to a government that can direct it.
As I finalise this post, the US government has ordered Anthropic to suspend access to its two most capable models (Fable 5 and Mythos 5) for any foreign national worldwide, including its own foreign-national staff. The stated concern is a potential jailbreak. The practical effect is that both models go dark for every customer immediately. Anthropic publicly disagrees, and complies anyway18. A model deployed to hundreds of millions of users can be withdrawn by government order overnight, and the supplier you depend on has no choice but to comply.
What a compromise costs you
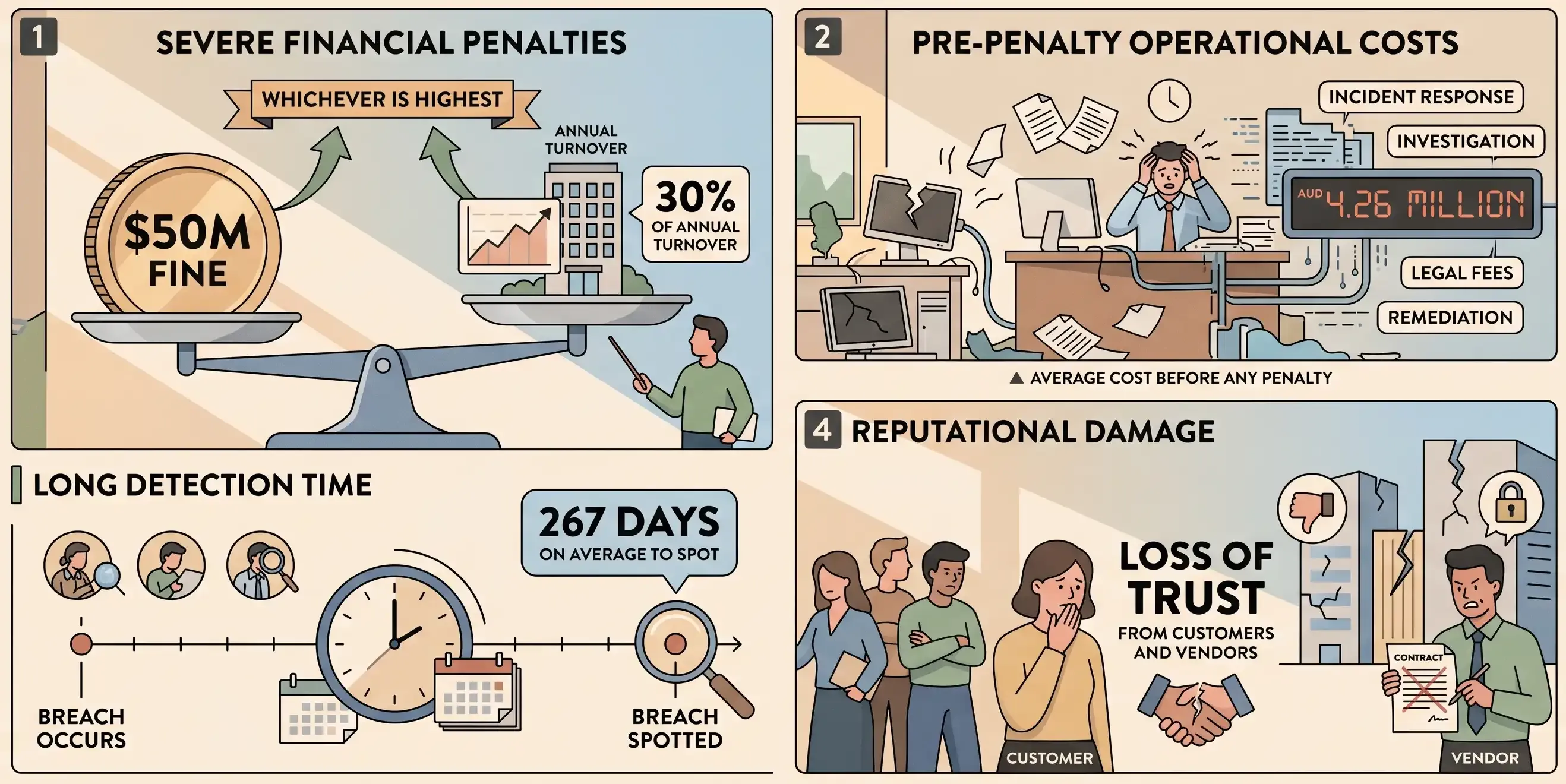
It doesn’t matter which layer the compromise comes through. For an Australian organisation the consequence is the same. The Privacy Act treats malicious code you installed exactly like malicious code you wrote. The duty to assess the breach and notify falls on whoever held the data, and the clock is tight: from the moment you have reasonable grounds to suspect personal information was reached, you have 30 days to assess it.19 The catch is that you often don’t realise a dependency was compromised until weeks later, and the attacker has already spent those weeks inside.
Those obligations now carry real teeth. The December 2024 amendments lifted the maximum penalty for a serious or repeated breach to AUD 50 million, three times the benefit gained, or 30% of company turnover, whichever is greatest.20 The average breach in Australia costs AUD 4.26 million before any penalty is added. And breaches that come in through a supplier are the hardest to catch, because they arrive on trust the business has already given. On average, they take 267 days to spot.21
maximum penalty for a serious or repeated breach to AUD 50 million, three times the benefit gained, or 30% of company turnover, whichever is greatest
Recent Australian breaches put real numbers on this. When Optus lost the records of about 9.5 million customers in 2022, it set aside AUD 140 million for the clean-up, and it now faces both a regulator’s civil penalty action and a class action that lawyers expect to run into the billions.22 Medibank’s breach the same year exposed the health data of 9.7 million people; the prudential regulator ordered it to hold an extra AUD 250 million in capital, on top of more than AUD 125 million in direct costs and several class actions still before the courts.23 Neither company installed malicious code, and both are still paying years later.
Qantas is the case that fits this post most closely. In 2025, attackers never touched its own systems. They got in through a third-party platform its customer service centre relied on, and took the records of 5.7 million customers.24 That is the supply chain route, arriving through a supplier the business had already trusted. The board cut executive bonuses in response.
The company pays the fine, and keeps paying in lost trust long after it’s settled. The board answers for both. “We left it to the engineers” is not something a director can say after the fact and keep their seat.
What to do this week
This is a starting point. Post 3 goes deeper into the technical defences. If you fund AI engineering, here are five questions to put to your team this week. Answering them costs nothing but an honest hour. The fixes may cost money later; knowing where you stand does not, and it beats finding out the hard way.
-
“If an engineer installed a malicious package on their laptop today, what would it reach?” The LiteLLM, Lightning, and Mini Shai-Hulud attacks all worked the same way. They stole whatever credentials sat on the engineer’s machine and used them to spread. A good answer is “a sandbox or a scoped credential set, nothing else.” A bad answer is “everything the engineer has access to, which includes our production cloud account.” A “let me check” answer is the most informative of all, because it tells you no one has thought about it.
-
“For every model we downloaded and run ourselves, do we know who published it and whether it is the original?” This applies to open-weight models your team downloads and runs, not to models you only call through an API. Major publishers have largely closed the file-format risk by defaulting to safer formats; the remaining risk is that the model your engineer pulled was not from the original publisher at all, but from a community uploader who modified, quantized, or fine-tuned it. If the team cannot answer for each model, that is your first audit.
-
“How many MCP servers are installed across the engineering team, who approved each one, and has anyone read the source?” MCP servers are the newest and least-audited layer in the stack. The answer should be a list, not a guess. If the team cannot produce the list, producing one is the action.
-
“For every AI assistant we run that can read company documents, do we know which documents it can see, and who can put text in front of it?” This is the RAG question. Any assistant that reads your internal documents to answer questions inherits the trust of every document it can see. EchoLeak showed that an attacker who can plant text in any of those documents (including a customer email or a supplier contract) can cause the AI to act on hidden instructions. The answer should be two lists: which documents each assistant can read, and which external parties can write into any of them. If the team cannot produce either, that is your RAG audit.
-
“For every model and AI service we depend on, do we know which jurisdiction the publisher operates under?” This is the sovereignty question. The answer should be a list mapping each model and service to a country, because each one exposes the stack to that country’s export controls, content rules, and possible compelled changes. For hosted services, the answer should also include where your prompts and customer data end up. If the team cannot produce the list, that is your sovereignty audit.
A confident answer to all five puts the team ahead of the field. A “let me get back to you” is where the work begins.
Footnotes
-
“Security Update: Suspected Supply Chain Incident”. liteLLM. Retrieved 29 May 2026 — vendor post-incident report;
litellmversions 1.82.7 and 1.82.8 were live on PyPI from 10:39 UTC on 24 March 2026 “for about 40 minutes before being quarantined by PyPI”. See also BleepingComputer’s coverage of the TeamPCP compromise. ↩ -
“How the PyTorch Lightning Community Discovered a Supply Chain Attack and Fixed it in 42 Minutes”. Lightning AI. Retrieved 29 May 2026 — vendor post-incident report;
lightningPyPI versions 2.6.2 and 2.6.3, April 2026. Discovered by Socket; confirmed in Lightning-AI GitHub issue #21689. ↩ -
“Mini Shai-Hulud strikes again: TanStack + more npm packages compromised”. Wiz. Retrieved 29 May 2026 — package count (~171 across npm and PyPI in the May wave) per Cloud Security Alliance’s research note on the Mini Shai-Hulud campaign; see also BleepingComputer. ↩
-
“Anthropic MCP design vulnerability enables RCE, threatening AI supply chain”. The Hacker News. Retrieved 30 May 2026 — ~7,000 public servers and software packages totalling more than 150 million downloads affected. See also Infosecurity Magazine. ↩
-
“Gemma 4: byte for byte, the most capable open models”. Google. Retrieved 7 June 2026. ↩
-
“Why open-weight models without guardrails are an AI safety risk”. NPR. Retrieved 7 June 2026 — NCITE research: abliterated models on Hugging Face grew from ~600 in 2024 to >6,000 by mid-2026. ↩
-
Egashira et al., “Exploiting LLM Quantization”. arXiv. Retrieved 7 June 2026 — a model that behaves benignly in full precision but exhibits adversary-chosen behaviour only after quantization for local deployment. ↩
-
“Data scientists targeted by malicious Hugging Face ML models with silent backdoor”. JFrog. Retrieved 29 May 2026. ↩
-
“Malicious ML models found on Hugging Face”. The Hacker News. Retrieved 29 May 2026 — malformed pickle files bypassed Hugging Face’s PickleScan; three zero-days disclosed. ↩
-
“Silent sabotage: hijacking Hugging Face’s safetensors conversion service”. HiddenLayer. Retrieved 29 May 2026. ↩
-
“Gemma 4 Usage Guide”. vLLM Recipes. Retrieved 7 June 2026 — Gemma 4 requires
trust_remote_code=Trueto load. ↩ -
“Hugging Face Transformers RCE flaw enables stealthy compromise via AI model configs”. CSO Online. Retrieved 7 June 2026 — CVE-2026-4372: RCE at
from_pretrained()via a malicious config field, notrust_remote_code=Truerequired. Transformers 4.56.0–5.2.x; patched in v5.3.0. ↩ -
“Zero-click AI vulnerability exposes Microsoft 365 Copilot data without user interaction”. The Hacker News. Retrieved 14 June 2026 — CVE-2025-32711 (CVSS 9.3), June 2025, discovered by Aim Labs: zero-click indirect prompt injection in Microsoft 365 Copilot, exfiltrating RAG context via a crafted external email. See also the arXiv writeup. ↩
-
“DLP policy for Copilot bug exposes confidential email”. Office 365 for IT Pros (Tony Redmond). Retrieved 14 June 2026 — from 21 January 2026 a defect in M365 Copilot (service advisory CW1226324) let it read and summarise emails carrying Purview sensitivity labels, bypassing DLP rules; Microsoft’s fix rolled out by mid-February 2026. ↩
-
“Interim Measures for the Management of Generative Artificial Intelligence Services”. China Law Translate. Retrieved 7 June 2026 — China’s CAC Interim Measures (effective August 2023), Article 4: providers must uphold “core socialist values”, refuse politically sensitive content, and file with the CAC. See also Hogan Lovells’ analysis. ↩
-
“U.S. Department of Commerce expands controls on advanced semiconductors and establishes new controls on closed AI model weights”. Hogan Lovells. Retrieved 7 June 2026 — January 2025 BIS framework: export controls on advanced AI chips and model weights; the weight rule was rescinded May 2025, the China chip regime remains active. ↩
-
Carl Franzen, “Alibaba’s Qwen3.7-Plus supports text, video and imagery inputs at low cost of $0.4/$1.6 per 1M token — but it’s proprietary”. VentureBeat. Retrieved 7 June 2026. ↩
-
“Statement on the US government directive to suspend access to Fable 5 and Mythos 5”. Anthropic. Retrieved 14 June 2026 — directive issued 12 June 2026 requiring Anthropic to suspend Fable 5 and Mythos 5 for all foreign nationals worldwide; other models unaffected. Anthropic disagreed: “the finding of a narrow potential jailbreak should [not] be cause for recalling a commercial model deployed to hundreds of millions of people”. ↩
-
“Part 4: Notifiable Data Breach (NDB) Scheme”. Office of the Australian Information Commissioner. Retrieved 8 June 2026 — Privacy Act 1988 (Cth) Part IIIC. s.26WH(2): 30-day maximum to assess a suspected eligible data breach. s.26WL(3): notify as soon as practicable once reasonable grounds exist. Applies to APP entities, including Australian businesses with turnover above AUD 3M. ↩
-
“Guide to privacy regulatory action”. Office of the Australian Information Commissioner. Retrieved 14 June 2026 — Privacy Act 1988 (Cth) s 13G: for a serious or repeated interference, the maximum penalty for a body corporate is the greater of AUD 50 million, three times the benefit obtained, or 30% of adjusted turnover during the breach turnover period. ↩
-
“Cost of a Data Breach Report 2025”. IBM. Retrieved 14 June 2026 — supply chain and third-party compromise took 267 days on average to identify and contain, the longest-dwell category of any attack vector (2025 report). The AUD 4.26 million figure is Australia’s most recent country-specific average, a record high reported in the 2024 country breakdown and still cited as the current record through 2025; see TechRepublic and IT Brief. ↩
-
“Australian Information Commissioner takes civil penalty action against Optus”. Office of the Australian Information Commissioner. Retrieved 18 June 2026 — the OAIC’s 2022 breach action covers about 9.5 million people; Optus flagged ~AUD 140 million in costs, with a class action also on foot. ↩
-
“Data breach to cost Medibank more than $125m”. Information Age (ACS). Retrieved 18 June 2026 — the 2022 breach hit 9.7 million customers; APRA imposed a AUD 250 million capital charge on top of more than AUD 125 million in direct costs. ↩
-
“Qantas confirms 5.7 million customers impacted by data breach”. TechRadar Pro. Retrieved 18 June 2026 — 2025 breach reached customer records through a third-party contact-centre platform; the board cut executive short-term pay by 15%. ↩